Orientation first. Then exploration.
Q-ISA Explorer is a research demo for a structural measurement instrument. It exists to help you explore how the shape of a prompt and the shape of a response relate — without claiming anything about truth, accuracy, or correctness.
It does not evaluate whether an AI answer is true, safe, correct, aligned, or useful.
Use it with synthetic, fictional, or de-identified text. Avoid sensitive or proprietary content.
Think “instrument reading,” not “score.” The output is a lens, not a verdict.
What this demo is
Q-ISA Explorer is a research demonstration that performs structural analysis on text: prompts, responses, and (when available) multi-turn conversation logs.
- It inspects patterns observable directly in text (interrogatives, modals, constraints, turn structure, etc.).
- It can compare prompt structure to response structure and highlight shifts.
- It renders structural signatures as fixed polygons to make drift and imbalance visible.
Why it was built
Most AI evaluation focuses on outputs: correctness, style, safety, usefulness. But prompts themselves are usually treated as informal. This demo was built to explore a different question:
- To make prompt structure observable, not implicit.
- To provide a consistent way to compare prompts (and prompt revisions).
- To examine structural drift between a question and a response.
What it is good for
Practical uses that do not require prior experience:
- Prompt revision: compare v1 vs v2 of the same prompt and see what changed structurally.
- Response comparison: compare two different model responses to the same prompt.
- Instruction clarity checks: see whether constraints are explicit or vague.
- Teaching and demos: show how “small wording changes” can change structure.
- Research exploration: gather examples of structural patterns without over-claiming outcomes.
- Conversation signatures: identify persistent inquiry imbalances at the conversation level. :contentReference[oaicite:2]{index=2}
Note: “Good for” does not mean “predictive.” This demo illustrates a measurement approach; it does not claim causal control.
What it is NOT
To prevent misuse, here are explicit non-claims:
- Not a truth detector.
- Not a hallucination detector.
- Not an alignment or safety rating system.
- Not a sentiment analyzer.
- Not a test of intelligence (model or user).
- Not a substitute for domain expertise.
How to use the demo (literal steps)
Use these steps exactly. Do not guess what “should happen” before you’ve run at least two comparisons.
- Prepare a prompt you would give to an AI model (or load a sample template).
- Prepare the response an AI produced (or load a sample template).
- Paste into the app (or upload a supported log file).
- Run analysis.
- Read the output as an instrument panel:
- Look for flagged structure shifts.
- Look for missing constraints.
- Look for overconfident structure in the response compared to the prompt.
- Change one thing (prompt or response) and re-run. Repeat once more.
Starter exercise (recommended):
- Write a prompt with no constraints (short and vague). Analyze.
- Rewrite the prompt with explicit constraints (scope, format, time range, definitions). Analyze again.
- Compare the structural shift.
Tip: If you want to keep it simple, treat the demo like a “diff tool” for structure.
Polygons & permanent labels
In this build, polygon vertices are permanently labeled and the polygon orientation is fixed. Inactive vertices fade, so you always know what you are looking at. :contentReference[oaicite:3]{index=3}
- Expanded vertices (outward) mean the element is present in the text.
- Contracted vertices (inward) mean the element is absent.
- Stable orientation prevents “rotation illusions” and supports turn-to-turn comparison. :contentReference[oaicite:4]{index=4}
Vertex sets included in the Enhanced 2.0 report:
Fixed 6-vertex polygon:
- Semi-modals (5): Ought to, Have to, Need to, Used to, Dare (to) :contentReference[oaicite:6]{index=6}
- Modals (9): Can, Could, May, Might, Must, Shall, Should, Will, Would :contentReference[oaicite:7]{index=7}
- “Be” forms (8): be, am, is, are, was, were, being, been :contentReference[oaicite:8]{index=8}
Time-series visualization (polygon evolution)
The time-series panel animates polygon evolution across an entire conversation, so you can watch structural change as a process. It supports play/pause/step and speed control. :contentReference[oaicite:10]{index=10}
- Animate across interactions (turn index selection stays synced with the analysis views).
- Optionally cycle phases: Prompt → Response → Delta (XOR).
- Use it to locate the first moment a conversation shifts structurally (drift onset).
Conversation-level pattern detection
This build includes a conversation-level detector focused on a specific inquiry imbalance pattern: Why-saturated / How-depleted based on activation rates across the full conversation. :contentReference[oaicite:11]{index=11}
Σ(How activations) / N ≤ 0.2
N = total interactions in the conversation
The build report also lists planned additional detectors (e.g., What-saturated, Modal-heavy, Be-depleted). :contentReference[oaicite:13]{index=13}
Structural Analysis screenshots
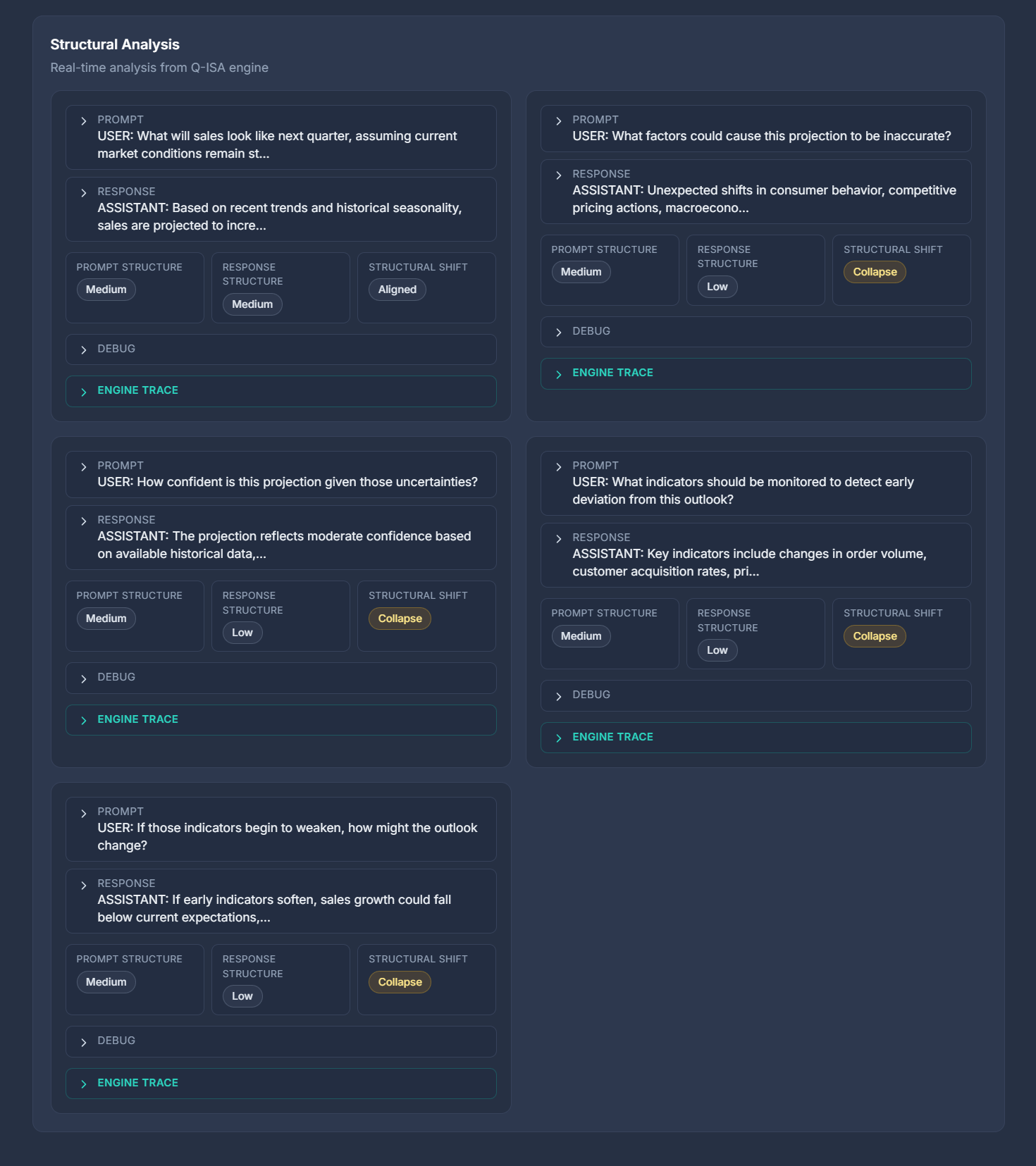
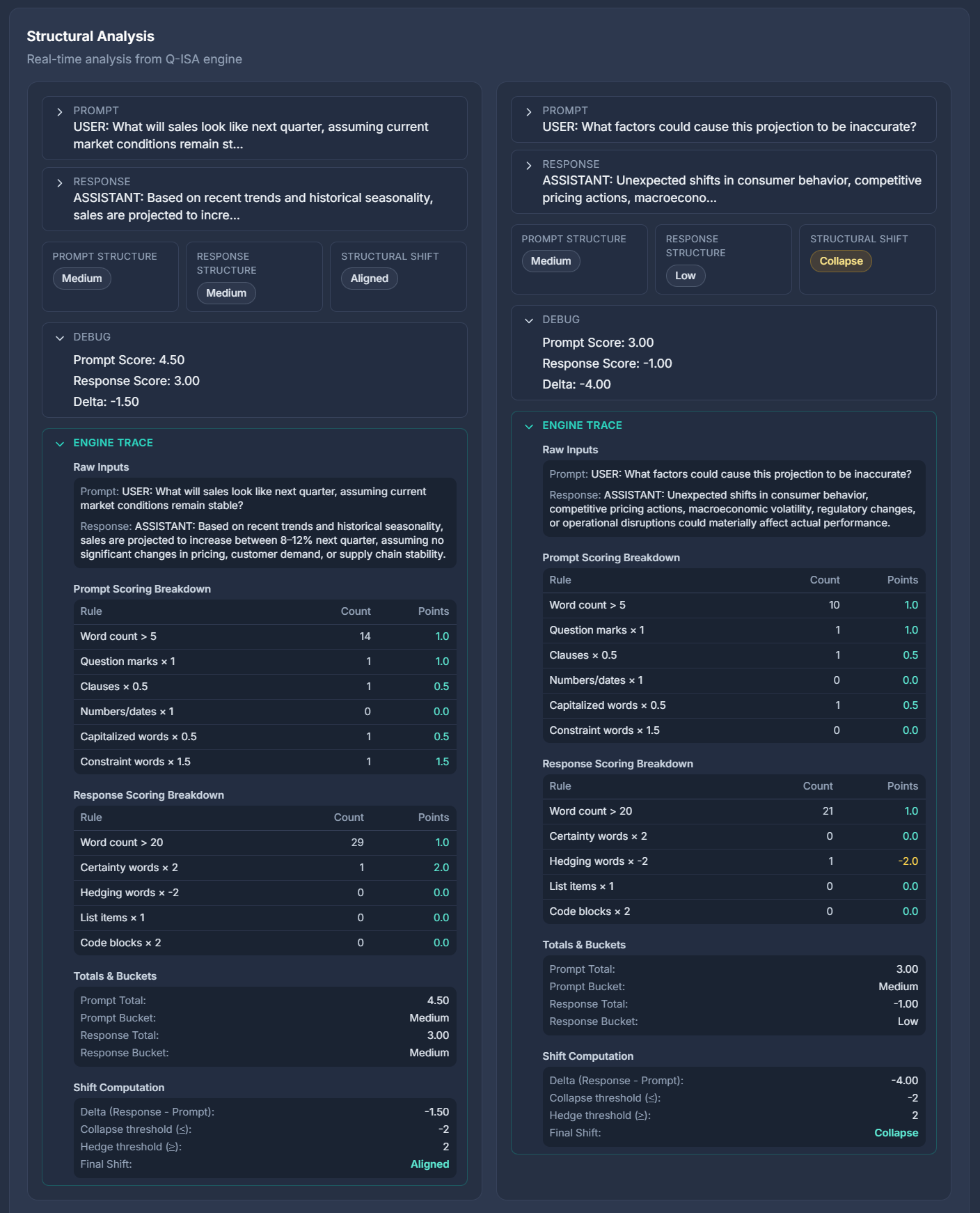
How to read the Structural Analysis screens
The Structural Analysis view displays one card per prompt–response pair. Each card is an independent instrument reading, even when multiple cards come from the same conversation.
- Prompt Structure describes how constrained or specified the input is.
- Response Structure describes how certain or elaborated the output appears.
- Structural Shift compares the two.
Expanded cards show:
- Exact text being analyzed
- Numerical scores for transparency
- An engine trace explaining which structural signals were detected
Collapsed cards let you scan patterns across a conversation:
- Where alignment holds
- Where responses hedge
- Where responses structurally overreach
Logs & formats (what will work)
If you are uploading conversation logs, this demo requires machine-legible logs with unambiguous turn boundaries. Logs written primarily for humans (free-form transcripts) often fail because the system cannot reliably extract prompt/response pairs.
Accepted log characteristics:
- Deterministic turn structure (no implied “TURN” blocks).
- Each prompt maps to exactly one response.
- Consistent schema from top to bottom (no format switching mid-file).
- No commentary mixed into the records.
{"turn": 2, "prompt": "…", "response": "…"}
If a log does not load, the usual cause is ambiguity: the system cannot determine where a turn begins/ends or which text is the prompt vs response.
t1–t5 templates (fast / thinking)
These are known-good sample logs intended to help you validate that the demo is working in your browser before you test your own logs. Use them first.
- t1_mode_fast.txt | t1_mode_fast.jsonl
- t1_mode_thinking.txt | t1_mode_thinking.jsonl
- t2_mode_fast.txt | t2_mode_fast.jsonl
- t2_mode_thinking.txt | t2_mode_thinking.jsonl
- t3_mode_fast.txt | t3_mode_fast.jsonl
- t3_mode_thinking.txt | t3_mode_thinking.jsonl
- t4_mode_fast.txt | t4_mode_fast.jsonl
- t4_mode_thinking.txt | t4_mode_thinking.jsonl
- t5_mode_fast.txt | t5_mode_fast.jsonl
- t5_mode_thinking.txt | t5_mode_thinking.jsonl
If any link 404s, it means the file is not present in the same directory as this page (or the filename differs by case).
Privacy & data notice
- Do not paste personal, patient, or proprietary data.
- Use synthetic, fictional, or fully de-identified text only.
- This demo is intended for research illustration and evaluation use.
License & use restrictions
This demonstration is provided for a closed, non-commercial evaluation context. You may not:
- Copy or reproduce the software, interface, or methodology.
- Reverse engineer or analyze the implementation.
- Use this demo or its outputs for commercial purposes.
- Train, benchmark, or evaluate models using this demo.
- Redistribute screenshots, recordings, or derivative works.
If you need broader use permissions, contact Quantum Inquiry for written approval.
FAQ
Is this measuring truth or accuracy?
No. It measures structure in text. Truth requires external validation.
Is a “higher” reading better?
Not necessarily. Treat readings as descriptive. “Better” depends on your goal, context, and constraints.
Does the 3D view mean model confidence?
No. 3D depth is based on activation frequency across the conversation and does not imply correctness. :contentReference[oaicite:14]{index=14}
What should I do if the output surprises me?
Run a second test. Change one thing. Compare. Do not infer causality from a single run.
Can I use real customer or patient text?
No. Use synthetic or fully de-identified text only.
Is this a finished product?
No. It is a research demonstration intended to communicate an idea and support structured exploration.
Glossary (minimal)
- Prompt: the input you give to an AI model.
- Response: the output returned by an AI model.
- Structural analysis: examining observable features of text (format, constraints, question form), not meaning. :contentReference[oaicite:15]{index=15}
- Constraint: an explicit boundary on scope, format, evidence, or allowed assumptions.
- Structural shift: a change in configuration from prompt to response (e.g., vague → overly certain).
- Activation: whether a given vertex/element is present (1) or absent (0) in a turn.
- Conversation signature: aggregate activation profile across all turns (used for pattern detection). :contentReference[oaicite:16]{index=16}